


With the growing competition of e-commerce platforms, OTT channels, or any B2C application, the success of activating and retaining customers revolves around how well customers are engaged.
Undoubtedly, customer engagement is a fundamental attribute of the growing and thriving success of commerce and online platforms.
In this article, we’ll talk about personalization and how to use it to drive product growth. Let’s get started!
Table of contents
- What is personalization?
- Benefits of personalization within products
- What is a recommendation engine or system?
- The roles and responsibilities of product managers to build AI and ML-based products
- Example of PMs influencing product personalization
- What are the different types of recommendation systems?
- How to track and measure the value of the recommendation system
- Tips and tactics
- The relationship between model metrics and business metrics
What is personalization?
At the onset of online applications, most commerce and OTT platforms focused on providing world-class customer shopping or browsing experience by making payments, checkout, catalogs, and order experiences flawless throughout the customer journey.
However, the online space has grown and matured exponentially in the past few years. It’s also resulted in massive amounts of data, like customer purchases history and cognitive data, for example, which can satisfy the growing breed of demanding, well-informed customers who possess a lot of digital knowledge amid many options.
Hence, these customers behave more cautiously while making purchase decisions. Moreover, they prefer choosing an intuitive platform that takes less time to find a service or product among various applications.
The winning recipe of successful online platforms, such as Amazon, eBay, Shopify, Netflix, Google Maps, Copilot, and other best-in-breed applications, is that they believe in giving customers beyond a browsing and shopping experience through their personalization strategy.
Amazon’s recommendation system is one of the best examples. Additionally, Netflix and Udemy are a few examples that use personalization as their core business model strategy to outperform the growing competition. They invested money, time, effort, and strategy into machine learning (ML) and state-of-art deep learning to build recommendation engines that continuously work towards scaling up personalization to its highest maturity in the future.
Benefits of personalization within products
The advantages of personalization are tailored, meaningful, and customer-focused offerings with the help of data. Based on recent research by McKinsey, personalization can create $1.7–$3 trillion in value. Another study shows that 35 percent of purchases on Amazon and 75 percent of picks on Netflix are outcomes of a product recommendations engine that gives a personalized experience for the customer.
In day-to-day digital life, regular encounters with personalization occur on everyday apps. For instance, Amazon’s product recommendation brings both upsell and cross-sell revenue, and Spotify’s recommended music sets it apart from its competitors, the next one to notice.
Likewise, YouTube recommends shorts, music, and vlogs based on user browsing history, preference, profile, or behavior. Movies, series and documentary ratings, and recommendations on Netflix and Hotstar help users make decisions faster and engage them in exploring new things — a core product strategy for these OTT apps.
What is a recommendation engine or system?
A recommendation engine is a powerful machine-learning system that allows customers to make choices quickly and helps them explore and buy interesting and relevant products.
Imagine an OTT platform like Netflix or an e-commerce platform like Amazon without a recommendation system. Will it be the same fun and attraction for picking a series or buying a product through this app?
If you’d like a more formal definition, “a recommendation system is driven by a set of AI/ML algorithms that run over customers’ past purchase history, cognitive behavior, and profile to predict what they want or looking for and, at times, psychologically persuade them to make a purchase decision.”
The roles and responsibilities of product managers to build AI and ML-based products
It is important to understand the roles and responsibilities of a product manager who builds machine learning products. Their role is similar to any other product manager. All desired PM skills and tactics are needed to build a powerful search engine, recommendation engine, or AI/Ml-driven products.
In addition, they must understand the underlying customer problems and challenges to justify the business’s need for an AI/ML/neural network (NN) or deep learning (DL) product. This justification of these products’ business value must be assessed at every stage, starting from building, enhancing, or scaling, since lots of effort, risk, time, and a large amount of capital are at stake while evolving them.
Other than generic product management skills, a PM must possess knowledge of specific data science concepts. PMs must know model deployment stages, test, and validation methods. They must have an in-depth understanding of data-supervised and unsupervised learning, AI frameworks, and libraries, such as PyTorch and TensorFlow. They also must know the types of the model: regression, classification, decision tree (DT), NN, DL, and natural language processing (NLP), as well as their pros and cons.
This makes PMs suitable to propose a solution based on the business need and customer problems. Nonetheless, a PM with these skill sets comfortably quantifies and initiates the conversation with AI/ML business leaders and experienced data scientists.
In the below example, I would demonstrate a simple and hypothetical case from e-commerce to exhibit the combination of the knowledge of basic PM activities used for building an AI/ML-based recommendation system from scratch.
Example of PMs influencing product personalization
Let’s say a PM has proposed a recommendation system to provide a personalized experience to customers on a commerce app. In this example, the PM has proposed personalization at scale through recommendation systems, based on a state-of-art deep learning algorithm.
To initiate this, the PM first identifies the problem and pain points of the customer through qualitative and quantitative ways. Later, the PM proposes a solution but ensures to start small and move incrementally towards the final goal of “personalization at scale.”
To conclude, the PM follows the build, measures, and learns an approach to building a recommendation system quickly and proposes scaling it up through complex models in the future. They will be tracking improvements at each milestone to assess the business impact coming through it:
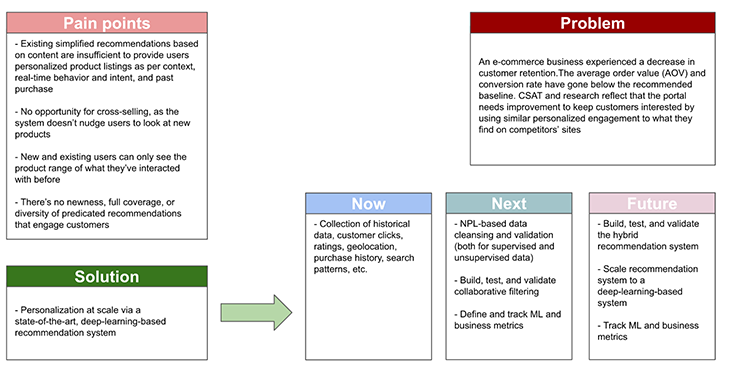
Building the recommendation system helps the organization use the manpower, cost, and effort estimation, as well as create value continuously towards long-term scalability goals. In this approach, the PM can easily influence high-tech stakeholders to solve the right problem.
What are the different types of recommendation systems?
There are different types of recommendation systems, and each one has its properties, advantages, and disadvantages. We’ll go over the most commonly known ones below!
1. Content-based filtering
This basic recommendation system uses the user profile information, such as their likes and dislikes, and generates recommendations.
- Advantages: cost-effective, does not need data about other users, scalable
- Disadvantages: recommend only based on users’ existing likes and dislikes
- Popular algorithm: cosine similarity
2. Collaborative filtering (CF)
It identifies the similarity between users based on their behavior exhibited on the application.
- Advantages: no need of product specific knowledge, not limited to users’ existing interest
- Disadvantages: cold start, scalability, and sparsity
- Popular algorithm: nearest neighbor algorithm, matrix factorization
3. Hybrid model
As the name suggests, the hybrid model combines collaborative and content-based filtering. As a result, it is a powerful recommendation system and provides accurate recommendations. This method also overcomes the challenges of sparsity and cold start.
- Advantages: no sparsity, no loss of information
- Disadvantages: expensive to implement, complex
4. Deep learning recommendation system
This is a powerful recommendation tool that can predict based on non-linear data of users and products. A simple example is the smart compose feature on Gmail that predicts a sentence’s next word. It has equal opportunity in commerce and retail too.
- Advantages: recommendations are based on real-time user activities. Scalable, accurate, relevant
- Disadvantages: complex, need a huge amount of data, may turn into a black box
- Popular algorithm: convolutional neural networks (CNN), recurrent neural network (RNN), CNN+RNN, Item2Vec
How to track and measure the value of the recommendation system
A product manager must understand how to measure the business’ success directly through the recommendation system. The most commonly used funnel and business metrics in this context are click-through rate (CTR), user engagement, retention, adoption, and loyalty.
Additionally, the impact of the recommendation system can also be tracked on sales and revenue by offering the tails of products that can complement current or previously purchased items by customers. It not only improves the sales of the top few trending items but also brings up several cross-sell and upsell products that lead to more purchases.
In terms of user engagement metrics, personalized recommendations significantly increase product exploration time. This is due to the personalized recommendations that, in return, impact downloads, purchases, subscription renewals, and CTR. Even this shows improvement in return customers through loyalty, session length, or site visits.
Besides, recommendations persuade users to choose a premium product instead of a low-budget product to maximize profit. For example, a big tail of recommended catalog products on an e-commerce app keeps the user engaged in the exploration. Additionally, it seizes their attention on items that might be paired or complemented with their desired products.
To make these business metrics show fast growth, the product team constantly tries to fine-tune the recommendation engine algorithm through A/B experiments to track the effect of changes.
Tips and tactics
Personalization strategy should align with the recommendation system goals and outcomes. For example, a content-based filtering recommendation system only makes recommendations based on a user’s interest.
Suppose the business goal is about the experience of discovering and recommending new interests to customers based on their behavior, contrasting with the concept of a content-based filtering solution. A standalone content-based model would not fulfill the goal unless it’s not scaled to collaborative filtering or a hybrid model.
To justify the ROI of the recommendation system, a PM ensures alignment between expected business goals and the final model scope in the roadmap.
Next, I will discuss how recommendation engine measures are tied up with business metrics performance. It is an important concept for a PM to know to lead a team of world-class data science engineers with confidence and knowledge.
The relationship between model metrics and business metrics
Besides business metrics, the product team must use standard machine learning evaluation metrics to measure the model’s success. The most common ones are:
- Precision@k: indicates how relevant the list of top k recommended items are
- Recall@k: indicates the coverage of all relevant items in the top k remediated items. Higher recall brings precision down, and vice versa
- Mean absolute error (MAE): helps predict the rating or accuracy to address how close predicted/recommended ratings are to users’ real ratings. It is also known as a loss function (L1 loss) that finds the absolute difference between the predicted and actual value
- Root mean square error (RMSE): another loss function, known as L2 loss. It is quadratic loss, as the prediction error is square, so it is never negative. A good model must have MSE close to zero
To understand the true meaning of these metrics, it is important to realize the task of the recommendation system and then track one of the few to evaluate the good performance. Then, as a PM, one can suggest which metrics to use (and which not to) to the engineering team, based on the underlying facts that point to common usages of the recommendation engine. They are classified widely under these three categories:
- Prediction: YouTube, Netflix, and Google news are important examples for predicting ratings and giving predictions to customers. This helps make decisions. For ratings, the recommended metrics are MAE and RMSE
- Ranking: a common task of e-commerce application remediation systems is the top K, or lists of recommended products staked in ranking. The common metrics are Precision@k and Recall@k. Other than this novelty, coverage, and pick rate are good metrics to track
- Classification: the expected outcome from the recommendation system is to determine a set of recommended items in no order. It could be similar items or users. For example, on Facebook, similar users with particular interests are recommended to be your friend. The metrics to evaluate this task could be simple decision-making based on the number of relevant or irrelevant recommended items. These numbers are placed on the contingency table and called a confusion matrix. The commonly known numbers from this confusion matrix are precision or true possible accuracy, fallout rate (false positive rate), and miss rate (false negative rate).

Business metrics
I’ve already explained business metrics in detail, but there’s an important relationship between ML metrics and business metrics. It’s stated that “performance exhibited by the recommendation system built for a business model should justify its ROI by tracking its implications on the business.”

In the case discussed above, the PM can define a few ML and business metrics to keep track of the improvement of the recommendation on his roadmap:

Conclusion
In a nutshell, the ultimate goal of personalization is to unlock the secret of customer intentions and behavior, and quickly serve them accurately based on what they are looking for.
The right service and product recommendations hook the customer with the application. There is a lot of opportunity to magnify the capability of a robust recommendation system with the help of a growing amount of customer data using NN, CNN, and DL.
Featured image source: IconScout
The post Product recommendation techniques that drive growth appeared first on LogRocket Blog.
from LogRocket Blog https://ift.tt/EqO2WIw
Gain $200 in a week
via Read more


